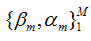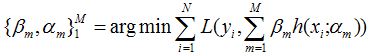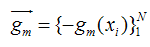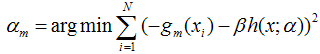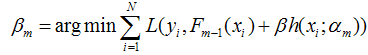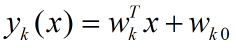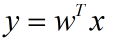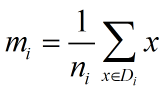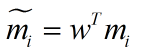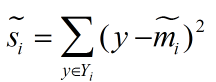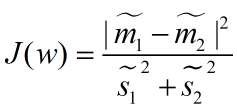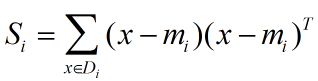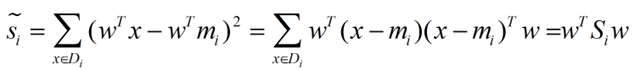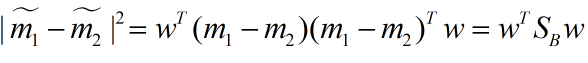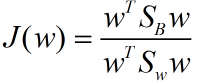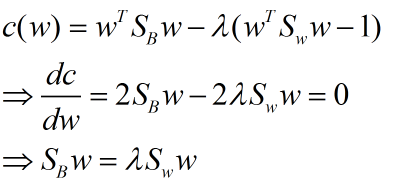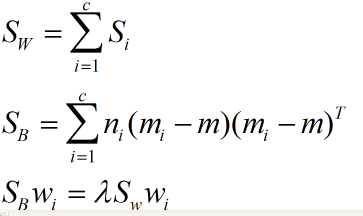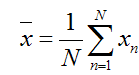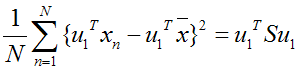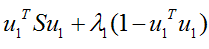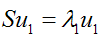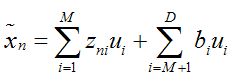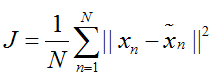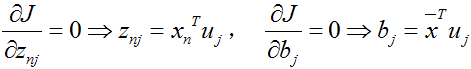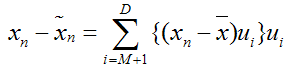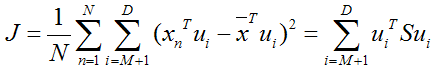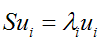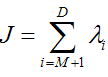版权声明:
本文由LeftNotEasy所有,发布于http://leftnoteasy.cnblogs.com。如果转载,请注明出处,在未经作者同意下将本文用于商业用途,将追究其法律责任。
前言:
上次写过一篇关于贝叶斯概率论的数学,最近时间比较紧,coding的任务比较重,不过还是抽空看了一些机器学习的书和视频,其中很推荐两个:一个是stanford的machinelearning公开课,在verycd可下载,可惜没有翻译。不过还是可以看。另外一个是prml-pattern recognitionand machine learning, Bishop的一部反响不错的书,而且是2008年的,算是比较新的一本书了。
前几天还准备写一个分布式计算的系列,只写了个开头,又换到写这个系列了。以后看哪边的心得更多,就写哪一个系列吧。最近干的事情比较杂,有跟机器学习相关的,有跟数学相关的,也有跟分布式相关的。
这个系列主要想能够用数学去描述机器学习,想要学好机器学习,首先得去理解其中的数学意义,不一定要到能够轻松自如的推导中间的公式,不过至少得认识这些式子吧,不然看一些相关的论文可就看不懂了,这个系列主要将会着重于去机器学习的数学描述这个部分,将会覆盖但不一定局限于回归、聚类、分类等算法。
回归与梯度下降:
回归在数学上来说是给定一个点集,能够用一条曲线去拟合之,如果这个曲线是一条直线,那就被称为线性回归,如果曲线是一条二次曲线,就被称为二次回归,回归还有很多的变种,如locallyweighted回归,logistic回归,等等,这个将在后面去讲。
用一个很简单的例子来说明回归,这个例子来自很多的地方,也在很多的opensource的软件中看到,比如说weka。大概就是,做一个房屋价值的评估系统,一个房屋的价值来自很多地方,比如说面积、房间的数量(几室几厅)、地段、朝向等等,这些影响房屋价值的变量被称为特征(feature),feature在机器学习中是一个很重要的概念,有很多的论文专门探讨这个东西。在此处,为了简单,假设我们的房屋就是一个变量影响的,就是房屋的面积。
假设有一个房屋销售的数据如下:
面积(m^2) 销售价钱(万元)
123 250
150 320
87 160
102 220
… …
这个表类似于帝都5环左右的房屋价钱,我们可以做出一个图,x轴是房屋的面积。y轴是房屋的售价,如下:
如果来了一个新的面积,假设在销售价钱的记录中没有的,我们怎么办呢?
我们可以用一条曲线去尽量准的拟合这些数据,然后如果有新的输入过来,我们可以在将曲线上这个点对应的值返回。如果用一条直线去拟合,可能是下面的样子:
绿色的点就是我们想要预测的点。
首先给出一些概念和常用的符号,在不同的机器学习书籍中可能有一定的差别。
房屋销售记录表 - 训练集(trainingset)或者训练数据(training data), 是我们流程中的输入数据,一般称为x
房屋销售价钱 - 输出数据,一般称为y
拟合的函数(或者称为假设或者模型),一般写做 y =h(x)
训练数据的条目数(#training set),一条训练数据是由一对输入数据和输出数据组成的
输入数据的维度(特征的个数,#features),n
下面是一个典型的机器学习的过程,首先给出一个输入数据,我们的算法会通过一系列的过程得到一个估计的函数,这个函数有能力对没有见过的新数据给出一个新的估计,也被称为构建一个模型。就如同上面的线性回归函数。
我们用X1,X2..Xn去描述feature里面的分量,比如x1=房间的面积,x2=房间的朝向,等等,我们可以做出一个估计函数:
θ在这儿称为参数,在这儿的意思是调整feature中每个分量的影响力,就是到底是房屋的面积更重要还是房屋的地段更重要。为了如果我们令X0= 1,就可以用向量的方式来表示了:
我们程序也需要一个机制去评估我们θ是否比较好,所以说需要对我们做出的h函数进行评估,一般这个函数称为损失函数(lossfunction)或者错误函数(errorfunction),描述h函数不好的程度,在下面,我们称这个函数为J函数
在这儿我们可以做出下面的一个错误函数:
这个错误估计函数是去对x(i)的估计值与真实值y(i)差的平方和作为错误估计函数,前面乘上的1/2是为了在求导的时候,这个系数就不见了。
如何调整θ以使得J(θ)取得最小值有很多方法,其中有最小二乘法(minsquare),是一种完全是数学描述的方法,在stanford机器学习开放课最后的部分会推导最小二乘法的公式的来源,这个来很多的机器学习和数学书上都可以找到,这里就不提最小二乘法,而谈谈梯度下降法。
梯度下降法是按下面的流程进行的:
1)首先对θ赋值,这个值可以是随机的,也可以让θ是一个全零的向量。
2)改变θ的值,使得J(θ)按梯度下降的方向进行减少。
为了更清楚,给出下面的图:
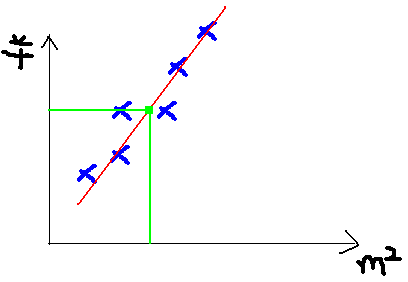
这是一个表示参数θ与误差函数J(θ)的关系图,红色的部分是表示J(θ)有着比较高的取值,我们需要的是,能够让J(θ)的值尽量的低。也就是深蓝色的部分。θ0,θ1表示θ向量的两个维度。
在上面提到梯度下降法的第一步是给θ给一个初值,假设随机给的初值是在图上的十字点。
然后我们将θ按照梯度下降的方向进行调整,就会使得J(θ)往更低的方向进行变化,如图所示,算法的结束将是在θ下降到无法继续下降为止。
当然,可能梯度下降的最终点并非是全局最小点,可能是一个局部最小点,可能是下面的情况:
上面这张图就是描述的一个局部最小点,这是我们重新选择了一个初始点得到的,看来我们这个算法将会在很大的程度上被初始点的选择影响而陷入局部最小点
下面我将用一个例子描述一下梯度减少的过程,对于我们的函数J(θ)求偏导J:(求导的过程如果不明白,可以温习一下微积分)
下面是更新的过程,也就是θi会向着梯度最小的方向进行减少。θi表示更新之前的值,-后面的部分表示按梯度方向减少的量,α表示步长,也就是每次按照梯度减少的方向变化多少。
一个很重要的地方值得注意的是,梯度是有方向的,对于一个向量θ,每一维分量θi都可以求出一个梯度的方向,我们就可以找到一个整体的方向,在变化的时候,我们就朝着下降最多的方向进行变化就可以达到一个最小点,不管它是局部的还是全局的。
用更简单的数学语言进行描述步骤2)是这样的:
倒三角形表示梯度,按这种方式来表示,θi就不见了,看看用好向量和矩阵,真的会大大的简化数学的描述啊。
总结与预告:
本文中的内容主要取自stanford的课程第二集,希望我把意思表达清楚了:)本系列的下一篇文章也将会取自stanford课程的第三集,下一次将会深入的讲讲回归、logistic回归、和Newton法,不过本系列并不希望做成stanford课程的笔记版,再往后面就不一定完全与stanford课程保持一致了。
前言:
距离上次发文章,也快有半个月的时间了,这半个月的时间里又在学习机器学习的道路上摸索着前进,积累了一点心得,以后会慢慢的写写这些心得。写文章是促进自己对知识认识的一个好方法,看书的时候往往不是非常细,所以有些公式、知识点什么的就一带而过,里面的一些具体意义就不容易理解了。而写文章,特别是写科普性的文章,需要对里面的具体意义弄明白,甚至还要能举出更生动的例子,这是一个挑战。为了写文章,往往需要把之前自己认为看明白的内容重新理解一下。
机器学习可不是一个完全的技术性的东西,之前和部门老大在outing的时候一直在聊这个问题,机器学习绝对不是一个一个孤立的算法堆砌起来的,想要像看《算法导论》这样看机器学习是个不可取的方法,机器学习里面有几个东西一直贯穿全书,比如说数据的分布、最大似然(以及求极值的几个方法,不过这个比较数学了),偏差、方差的权衡,还有特征选择,模型选择,混合模型等等知识,这些知识像砖头、水泥一样构成了机器学习里面的一个个的算法。想要真正学好这些算法,一定要静下心来将这些基础知识弄清楚,才能够真正理解、实现好各种机器学习算法。
今天的主题是线性回归,也会提一下偏差、方差的均衡这个主题。
线性回归定义:
在上一个主题中,也是一个与回归相关的,不过上一节更侧重于梯度这个概念,这一节更侧重于回归本身与偏差和方差的概念。
回归最简单的定义是,给出一个点集D,用一个函数去拟合这个点集,并且使得点集与拟合函数间的误差最小。
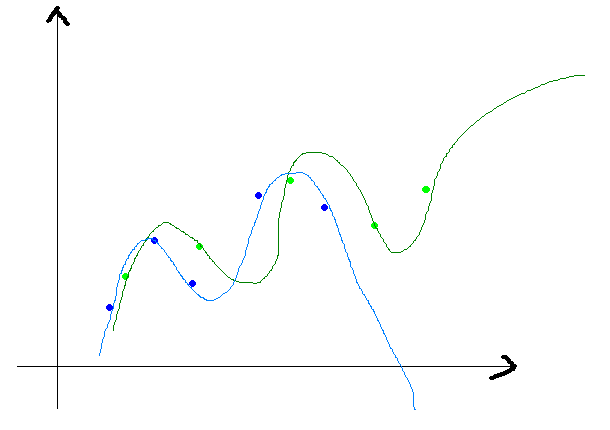
上图所示,给出一个点集(x,y),需要用一个函数去拟合这个点集,蓝色的点是点集中的点,而红色的曲线是函数的曲线,第一张图是一个最简单的模型,对应的函数为y = f(x)= ax + b,这个就是一个线性函数,
第二张图是二次曲线,对应的函数是y = f(x) = ax^2 + b。
第三张图我也不知道是什么函数,瞎画的。
第四张图可以认为是一个N次曲线,N = M - 1,M是点集中点的个数,有一个定理是,对于给定的M个点,我们可以用一个M -1次的函数去完美的经过这个点集。
真正的线性回归,不仅会考虑使得曲线与给定点集的拟合程度最好,还会考虑模型最简单,这个话题我们将在本章后面的偏差、方差的权衡中深入的说,另外这个话题还可以参考我之前的一篇文章:贝叶斯、概率分布与机器学习,里面对模型复杂度的问题也进行了一些讨论。
线性回归(linear regression),并非是指的线性函数,也就是
(为了方便起见,以后向量我就不在上面加箭头了)
x0,x1…表示一个点不同的维度,比如说上一节中提到的,房子的价钱是由包括面积、房间的个数、房屋的朝向等等因素去决定的。而是用广义的线性函数:
wj是系数,w就是这个系数组成的向量,它影响着不同维度的Φj(x)在回归函数中的影响度,比如说对于房屋的售价来说,房间朝向的w一定比房间面积的w更小。Φ(x)是可以换成不同的函数,不一定要求Φ(x)=x,这样的模型我们认为是广义线性模型。
最小二乘法与最大似然:
这个话题在此处有一个很详细的讨论,我这里主要谈谈这个问题的理解。最小二乘法是线性回归中一个最简单的方法,它的推导有一个假设,就是回归函数的估计值与真实值间的误差假设是一个高斯分布。这个用公式来表示是下面的样子:,y(x,w)就是给定了w系数向量下的回归函数的估计值,而t就是真实值了,ε表示误差。我们可以接下来推出下面的式子:
这是一个简单的条件概率表达式,表示在给定了x,w,β的情况下,得到真实值t的概率,由于ε服从高斯分布,则从估计值到真实值间的概率也是高斯分布的,看起来像下面的样子:
贝叶斯、概率分布与机器学习这篇文章中对分布影响结果这个话题讨论比较多,可以回过头去看看,由于最小二乘法有这样一个假设,则会导致,如果我们给出的估计函数y(x,w)与真实值t不是高斯分布的,甚至是一个差距很大的分布,那么算出来的模型一定是不正确的,当给定一个新的点x’想要求出一个估计值y’,与真实值t’可能就非常的远了。
概率分布是一个可爱又可恨的东西,当我们能够准确的预知某些数据的分布时,那我们可以做出一个非常精确的模型去预测它,但是在大多数真实的应用场景中,数据的分布是不可知的,我们也很难去用一个分布、甚至多个分布的混合去表示数据的真实分布,比如说给定了1亿篇网页,希望用一个现有的分布(比如说混合高斯分布)去匹配里面词频的分布,是不可能的。在这种情况下,我们只能得到词的出现概率,比如p(的)的概率是0.5,也就是一个网页有1/2的概率出现“的”。如果一个算法,是对里面的分布进行了某些假设,那么可能这个算法在真实的应用中就会表现欠佳。最小二乘法对于类似的一个复杂问题,就很无力了
偏差、方差的权衡(trade-off):
偏差(bias)和方差(variance)是统计学的概念,刚进公司的时候,看到每个人的嘴里随时蹦出这两个词,觉得很可怕。首先得明确的,方差是多个模型间的比较,而非对一个模型而言的,对于单独的一个模型,比如说:
这样的一个给定了具体系数的估计函数,是不能说f(x)的方差是多少。而偏差可以是单个数据集中的,也可以是多个数据集中的,这个得看具体的定义。
方差和偏差一般来说,是从同一个数据集中,用科学的采样方法得到几个不同的子数据集,用这些子数据集得到的模型,就可以谈他们的方差和偏差的情况了。方差和偏差的变化一般是和模型的复杂程度成正比的,就像本文一开始那四张小图片一样,当我们一味的追求模型精确匹配,则可能会导致同一组数据训练出不同的模型,它们之间的差异非常大。这就叫做方差,不过他们的偏差就很小了,如下图所示:
上图的蓝色和绿色的点是表示一个数据集中采样得到的不同的子数据集,我们有两个N次的曲线去拟合这些点集,则可以得到两条曲线(蓝色和深绿色),它们的差异就很大,但是他们本是由同一个数据集生成的,这个就是模型复杂造成的方差大。模型越复杂,偏差就越小,而模型越简单,偏差就越大,方差和偏差是按下面的方式进行变化的:
当方差和偏差加起来最优的点,就是我们最佳的模型复杂度。
用一个很通俗的例子来说,现在咱们国家一味的追求GDP,GDP就像是模型的偏差,国家希望现有的GDP和目标的GDP差异尽量的小,但是其中使用了很多复杂的手段,比如说倒卖土地、强拆等等,这个增加了模型的复杂度,也会使得偏差(居民的收入分配)变大,穷的人越穷(被赶出城市的人与进入城市买不起房的人),富的人越富(倒卖土地的人与卖房子的人)。其实本来模型不需要这么复杂,能够让居民的收入分配与国家的发展取得一个平衡的模型是最好的模型。
最后还是用数学的语言来描述一下偏差和方差:
E(L)是损失函数,h(x)表示真实值的平均,第一部分是与y(模型的估计函数)有关的,这个部分是由于我们选择不同的估计函数(模型)带来的差异,而第二部分是与y无关的,这个部分可以认为是模型的固有噪声。
对于上面公式的第一部分,我们可以化成下面的形式:
这个部分在PRML的1.5.5推导,前一半是表示偏差,而后一半表示方差,我们可以得出:损失函数=偏差^2+方差+固有噪音。
下图也来自PRML:
这是一个曲线拟合的问题,对同分布的不同的数据集进行了多次的曲线拟合,左边表示方差,右边表示偏差,绿色是真实值函数。lnlambda表示模型的复杂程度,这个值越小,表示模型的复杂程度越高,在第一行,大家的复杂度都很低(每个人都很穷)的时候,方差是很小的,但是偏差同样很小(国家也很穷),但是到了最后一幅图,我们可以得到,每个人的复杂程度都很高的情况下,不同的函数就有着天壤之别了(贫富差异大),但是偏差就很小了(国家很富有)。
前言:
本来上一章的结尾提到,准备写写线性分类的问题,文章都已经写得差不多了,但是突然听说最近Team准备做一套分布式的分类器,可能会使用RandomForest来做,下了几篇论文看了看,简单的randomforest还比较容易弄懂,复杂一点的还会与boosting等算法结合(参见iccv09),对于boosting也不甚了解,所以临时抱佛脚的看了看。说起boosting,强哥之前实现过一套GradientBoosting Descent Tree(GBDT)算法,正好参考一下。
最近看的一些论文中发现了模型组合的好处,比如GBDT或者rf,都是将简单的模型组合起来,效果比单个更复杂的模型好。组合的方式很多,随机化(比如randomforest),Boosting(比如GBDT)都是其中典型的方法,今天主要谈谈GradientBoosting方法(这个与传统的Boosting还有一些不同)的一些数学基础,有了这个数学基础,上面的应用可以看Freidman的GradientBoosting Machine。
本文要求读者学过基本的大学数学,另外对分类、回归等基本的机器学习概念了解。
本文主要参考资料是prml与Gradient Boosting Machine。
Boosting方法:
Boosting这其实思想相当的简单,大概是,对一份数据,建立M个模型(比如分类),一般这种模型比较简单,称为弱分类器(weaklearner)每次分类都将上一次分错的数据权重提高一点再进行分类,这样最终得到的分类器在测试数据与训练数据上都可以得到比较好的成绩。
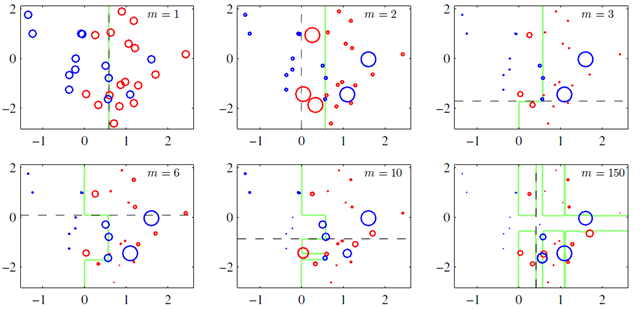
上图(图片来自prmlp660)就是一个Boosting的过程,绿色的线表示目前取得的模型(模型是由前m次得到的模型合并得到的),虚线表示当前这次模型。每次分类的时候,会更关注分错的数据,上图中,红色和蓝色的点就是数据,点越大表示权重越高,看看右下角的图片,当m=150的时候,获取的模型已经几乎能够将红色和蓝色的点区分开了。
Boosting可以用下面的公式来表示:
训练集中一共有n个点,我们可以为里面的每一个点赋上一个权重Wi(0 <= i <n),表示这个点的重要程度,通过依次训练模型的过程,我们对点的权重进行修正,如果分类正确了,权重提高,如果分类错了,则权重降低,初始的时候,权重都是一样的。上图中绿色的线就是表示依次训练模型,可以想象得到,程序越往后执行,训练出的模型就越会在意那些容易分错的点。当全部的程序执行完后,会得到M个模型,分别对应上图的y1(x)…yM(x),通过加权的方式组合成一个最终的模型YM(x)。
我觉得Boosting更像是一个人学习的过程,开始学一样东西的时候,会去做一些习题,但是常常连一些简单的题目都会弄错,但是越到后面,简单的题目已经难不倒他了,就会去做更复杂的题目,等到他做了很多的题目后,不管是难题还是简单的题都可以解决掉了。
GradientBoosting方法:
其实Boosting更像是一种思想,GradientBoosting是一种Boosting的方法,它主要的思想是,每一次建立模型是在之前建立模型损失函数的梯度下降方向。这句话有一点拗口,损失函数(lossfunction)描述的是模型的不靠谱程度,损失函数越大,则说明模型越容易出错(其实这里有一个方差、偏差均衡的问题,但是这里就假设损失函数越大,模型越容易出错)。如果我们的模型能够让损失函数持续的下降,则说明我们的模型在不停的改进,而最好的方式就是让损失函数在其梯度(Gradient)的方向上下降。
下面的内容就是用数学的方式来描述Gradient Boosting,数学上不算太复杂,只要潜下心来看就能看懂:)
可加的参数的梯度表示:
假设我们的模型能够用下面的函数来表示,P表示参数,可能有多个参数组成,P ={p0,p1,p2….},F(x;P)表示以P为参数的x的函数,也就是我们的预测函数。我们的模型是由多个模型加起来的,β表示每个模型的权重,α表示模型里面的参数。为了优化F,我们就可以优化{β,α}也就是P。
我们还是用P来表示模型的参数,可以得到,Φ(P)表示P的likelihood函数,也就是模型F(x;P)的loss函数,Φ(P)=…后面的一块看起来很复杂,只要理解成是一个损失函数就行了,不要被吓跑了。
既然模型(F(x;P))是可加的,对于参数P,我们也可以得到下面的式子: 这样优化P的过程,就可以是一个梯度下降的过程了,假设当前已经得到了m-1个模型,想要得到第m个模型的时候,我们首先对前m-1个模型求梯度。得到最快下降的方向,gm就是最快下降的方向。
这里有一个很重要的假设,对于求出的前m-1个模型,我们认为是已知的了,不要去改变它,而我们的目标是放在之后的模型建立上。就像做事情的时候,之前做错的事就没有后悔药吃了,只有努力在之后的事情上别犯错:
我们得到的新的模型就是,它就在P似然函数的梯度方向。ρ是在梯度方向上下降的距离。
我们最终可以通过优化下面的式子来得到最优的ρ:
可加的函数的梯度表示:
上面通过参数P的可加性,得到了参数P的似然函数的梯度下降的方法。我们可以将参数P的可加性推广到函数空间,我们可以得到下面的函数,此处的fi(x)类似于上面的h(x;α),因为作者的文献中这样使用,我这里就用作者的表达方法:
同样,我们可以得到函数F(x)的梯度下降方向g(x)
最终可以得到第m个模型fm(x)的表达式:
通用的Gradient Descent Boosting的框架:
下面我将推导一下GradientDescent方法的通用形式,之前讨论过的:
对于模型的参数{β,α},我们可以用下面的式子来进行表示,这个式子的意思是,对于N个样本点(xi,yi)计算其在模型F(x;α,β)下的损失函数,最优的{α,β}就是能够使得这个损失函数最小的{α,β}。 表示两个m维的参数:
写成梯度下降的方式就是下面的形式,也就是我们将要得到的模型fm(x)的参数{αm,βm}能够使得fm的方向是之前得到的模型Fm-1(x)的损失函数下降最快的方向:
对于每一个数据点xi都可以得到一个gm(xi),最终我们可以得到一个完整梯度下降方向
为了使得fm(x)能够在gm(x)的方向上,我们可以优化下面的式子得到,可以使用最小二乘法:
得到了α的基础上,然后可以得到βm。 最终合并到模型中:
算法的流程图如下
之后,作者还说了这个算法在其他的地方的推广,其中,Multi-class logistic regression andclassification就是GBDT的一种实现,可以看看,流程图跟上面的算法类似的。这里不打算继续写下去,再写下去就成论文翻译了,请参考文章:Greedyfunction Approximation – A Gradient BoostingMachine,作者Freidman。
总结:
本文主要谈了谈Boosting与GradientBoosting的方法,Boosting主要是一种思想,表示“知错就改”。而GradientBoosting是在这个思想下的一种函数(也可以说是模型)的优化的方法,首先将函数分解为可加的形式(其实所有的函数都是可加的,只是是否好放在这个框架中,以及最终的效果如何)。然后进行m次迭代,通过使得损失函数在梯度方向上减少,最终得到一个优秀的模型。值得一提的是,每次模型在梯度方向上的减少的部分,可以认为是一个“小”的或者“弱”的模型,最终我们会通过加权(也就是每次在梯度方向上下降的距离)的方式将这些“弱”的模型合并起来,形成一个更好的模型。
有了这个Gradient Descent这个基础,还可以做很多的事情。也在机器学习的道路上更进一步了:)
前言:
第二篇的文章中谈到,和部门老大一宁出去outing的时候,他给了我相当多的机器学习的建议,里面涉及到很多的算法的意义、学习方法等等。一宁上次给我提到,如果学习分类算法,最好从线性的入手,线性分类器最简单的就是LDA,它可以看做是简化版的SVM,如果想理解SVM这种分类器,那理解LDA就是很有必要的了。
谈到LDA,就不得不谈谈PCA,PCA是一个和LDA非常相关的算法,从推导、求解、到算法最终的结果,都有着相当的相似。
本次的内容主要是以推导数学公式为主,都是从算法的物理意义出发,然后一步一步最终推导到最终的式子,LDA和PCA最终的表现都是解一个矩阵特征值的问题,但是理解了如何推导,才能更深刻的理解其中的含义。本次内容要求读者有一些基本的线性代数基础,比如说特征值、特征向量的概念,空间投影,点乘等的一些基本知识等。除此之外的其他公式、我都尽量讲得更简单清楚。
LDA:
LDA的全称是Linear Discriminant Analysis(线性判别分析),是一种supervisedlearning。有些资料上也称为是Fisher’s Linear Discriminant,因为它被RonaldFisher发明自1936年,Discriminant这次词我个人的理解是,一个模型,不需要去通过概率的方法来训练、预测数据,比如说各种贝叶斯方法,就需要获取数据的先验、后验概率等等。LDA是在目前机器学习、数据挖掘领域经典且热门的一个算法,据我所知,百度的商务搜索部里面就用了不少这方面的算法。
LDA的原理是,将带上标签的数据(点),通过投影的方法,投影到维度更低的空间中,使得投影后的点,会形成按类别区分,一簇一簇的情况,相同类别的点,将会在投影后的空间中更接近。要说明白LDA,首先得弄明白线性分类器(LinearClassifier):因为LDA是一种线性分类器。对于K-分类的一个分类问题,会有K个线性函数:
当满足条件:对于所有的j,都有Yk >Yj,的时候,我们就说x属于类别k。对于每一个分类,都有一个公式去算一个分值,在所有的公式得到的分值中,找一个最大的,就是所属的分类了。
上式实际上就是一种投影,是将一个高维的点投影到一条高维的直线上,LDA最求的目标是,给出一个标注了类别的数据集,投影到了一条直线之后,能够使得点尽量的按类别区分开,当k=2即二分类问题的时候,如下图所示:
红色的方形的点为0类的原始点、蓝色的方形点为1类的原始点,经过原点的那条线就是投影的直线,从图上可以清楚的看到,红色的点和蓝色的点被原点明显的分开了,这个数据只是随便画的,如果在高维的情况下,看起来会更好一点。下面我来推导一下二分类LDA问题的公式:
假设用来区分二分类的直线(投影函数)为:
LDA分类的一个目标是使得不同类别之间的距离越远越好,同一类别之中的距离越近越好,所以我们需要定义几个关键的值。
类别i的原始中心点为:(Di表示属于类别i的点)
类别i投影后的中心点为:
衡量类别i投影后,类别点之间的分散程度(方差)为:
最终我们可以得到一个下面的公式,表示LDA投影到w后的损失函数:
我们分类的目标是,使得类别内的点距离越近越好(集中),类别间的点越远越好。分母表示每一个类别内的方差之和,方差越大表示一个类别内的点越分散,分子为两个类别各自的中心点的距离的平方,我们最大化J(w)就可以求出最优的w了。想要求出最优的w,可以使用拉格朗日乘子法,但是现在我们得到的J(w)里面,w是不能被单独提出来的,我们就得想办法将w单独提出来。
我们定义一个投影前的各类别分散程度的矩阵,这个矩阵看起来有一点麻烦,其实意思是,如果某一个分类的输入点集Di里面的点距离这个分类的中心店mi越近,则Si里面元素的值就越小,如果分类的点都紧紧地围绕着mi,则Si里面的元素值越更接近0.
带入Si,将J(w)分母化为:
同样的将J(w)分子化为:
这样损失函数可以化成下面的形式:
这样就可以用最喜欢的拉格朗日乘子法了,但是还有一个问题,如果分子、分母是都可以取任意值的,那就会使得有无穷解,我们将分母限制为长度为1(这是用拉格朗日乘子法一个很重要的技巧,在下面将说的PCA里面也会用到,如果忘记了,请复习一下高数),并作为拉格朗日乘子法的限制条件,带入得到:
这样的式子就是一个求特征值的问题了。
对于N(N>2)分类的问题,我就直接写出下面的结论了:
这同样是一个求特征值的问题,我们求出的第i大的特征向量,就是对应的Wi了。
这里想多谈谈特征值,特征值在纯数学、量子力学、固体力学、计算机等等领域都有广泛的应用,特征值表示的是矩阵的性质,当我们取到矩阵的前N个最大的特征值的时候,我们可以说提取到的矩阵主要的成分(这个和之后的PCA相关,但是不是完全一样的概念)。在机器学习领域,不少的地方都要用到特征值的计算,比如说图像识别、pagerank、LDA、还有之后将会提到的PCA等等。
下图是图像识别中广泛用到的特征脸(eigenface),提取出特征脸有两个目的,首先是为了压缩数据,对于一张图片,只需要保存其最重要的部分就是了,然后是为了使得程序更容易处理,在提取主要特征的时候,很多的噪声都被过滤掉了。跟下面将谈到的PCA的作用非常相关。
特征值的求法有很多,求一个D * D的矩阵的时间复杂度是O(D^3), 也有一些求Top M的方法,比如说power method,它的时间复杂度是O(D^2 * M),总体来说,求特征值是一个很费时间的操作,如果是单机环境下,是很局限的。
PCA:
主成分分析(PCA)与LDA有着非常近似的意思,LDA的输入数据是带标签的,而PCA的输入数据是不带标签的,所以PCA是一种unsupervisedlearning。LDA通常来说是作为一个独立的算法存在,给定了训练数据后,将会得到一系列的判别函数(discriminatefunction),之后对于新的输入,就可以进行预测了。而PCA更像是一个预处理的方法,它可以将原本的数据降低维度,而使得降低了维度的数据之间的方差最大(也可以说投影误差最小,具体在之后的推导里面会谈到)。
方差这个东西是个很有趣的,有些时候我们会考虑减少方差(比如说训练模型的时候,我们会考虑到方差-偏差的均衡),有的时候我们会尽量的增大方差。方差就像是一种信仰(强哥的话),不一定会有很严密的证明,从实践来说,通过尽量增大投影方差的PCA算法,确实可以提高我们的算法质量。
说了这么多,推推公式可以帮助我们理解。我下面将用两种思路来推导出一个同样的表达式。首先是最大化投影后的方差,其次是最小化投影后的损失(投影产生的损失最小)。
最大化方差法:
假设我们还是将一个空间中的点投影到一个向量中去。首先,给出原空间的中心点:
假设u1为投影向量,投影之后的方差为:
上面这个式子如果看懂了之前推导LDA的过程,应该比较容易理解,如果线性代数里面的内容忘记了,可以再温习一下,优化上式等号右边的内容,还是用拉格朗日乘子法:
将上式求导,使之为0,得到:
这是一个标准的特征值表达式了,λ对应的特征值,u对应的特征向量。上式的左边取得最大值的条件就是λ1最大,也就是取得最大的特征值的时候。假设我们是要将一个D维的数据空间投影到M维的数据空间中(M< D), 那我们取前M个特征向量构成的投影矩阵就是能够使得方差最大的矩阵了。
最小化损失法:
假设输入数据x是在D维空间中的点,那么,我们可以用D个正交的D维向量去完全的表示这个空间(这个空间中所有的向量都可以用这D个向量的线性组合得到)。在D维空间中,有无穷多种可能找这D个正交的D维向量,哪个组合是最合适的呢?
假设我们已经找到了这D个向量,可以得到:
我们可以用近似法来表示投影后的点:
上式表示,得到的新的x是由前M 个基的线性组合加上后D -M个基的线性组合,注意这里的z是对于每个x都不同的,而b对于每个x是相同的,这样我们就可以用M个数来表示空间中的一个点,也就是使得数据降维了。但是这样降维后的数据,必然会产生一些扭曲,我们用J描述这种扭曲,我们的目标是,使得J最小:
上式的意思很直观,就是对于每一个点,将降维后的点与原始的点之间的距离的平方和加起来,求平均值,我们就要使得这个平均值最小。我们令:
将上面得到的z与b带入降维的表达式:
将上式带入J的表达式得到:
再用上拉普拉斯乘子法(此处略),可以得到,取得我们想要的投影基的表达式为:
这里又是一个特征值的表达式,我们想要的前M个向量其实就是这里最大的M个特征值所对应的特征向量。证明这个还可以看看,我们J可以化为:
也就是当误差J是由最小的D - M个特征值组成的时候,J取得最小值。跟上面的意思相同。
下图是PCA的投影的一个表示,黑色的点是原始的点,带箭头的虚线是投影的向量,Pc1表示特征值最大的特征向量,pc2表示特征值次大的特征向量,两者是彼此正交的,因为这原本是一个2维的空间,所以最多有两个投影的向量,如果空间维度更高,则投影的向量会更多。
总结:
本次主要讲了两种方法,PCA与LDA,两者的思想和计算方法非常类似,但是一个是作为独立的算法存在,另一个更多的用于数据的预处理的工作。另外对于PCA和LDA还有核方法,本次的篇幅比较大了,先不说了,以后有时间再谈:













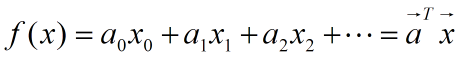
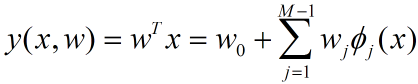
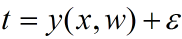




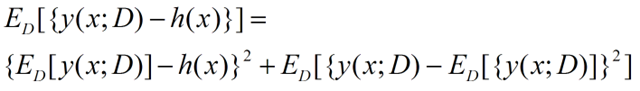


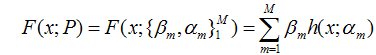
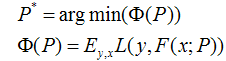
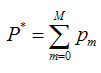
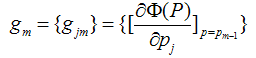


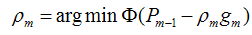



 表示两个m维的参数:
表示两个m维的参数: